| Name | labml-nn JSON |
| Version |
0.5.1
 JSON
JSON |
| download |
| home_page | https://github.com/labmlai/annotated_deep_learning_paper_implementations |
| Summary | 🧑🏫 Implementations/tutorials of deep learning papers with side-by-side notes 📝; including transformers (original, xl, switch, feedback, vit), optimizers (adam, radam, adabelief), gans(dcgan, cyclegan, stylegan2), 🎮 reinforcement learning (ppo, dqn), capsnet, distillation, diffusion, etc. 🧠 |
| upload_time | 2025-08-08 14:31:04 |
| maintainer | None |
| docs_url | None |
| author | Varuna Jayasiri, Nipun Wijerathne |
| requires_python | None |
| license | None |
| keywords |
machine
learning
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
torch
torchvision
torchtext
labml
labml-helpers
numpy
matplotlib
einops
gym
opencv-python
Pillow
faiss
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
[](https://twitter.com/labmlai)
# [labml.ai Deep Learning Paper Implementations](https://nn.labml.ai/index.html)
This is a collection of simple PyTorch implementations of
neural networks and related algorithms.
These implementations are documented with explanations,
[The website](https://nn.labml.ai/index.html)
renders these as side-by-side formatted notes.
We believe these would help you understand these algorithms better.
We are actively maintaining this repo and adding new
implementations almost weekly.
[](https://twitter.com/labmlai) for updates.
## Paper Implementations
#### ✨ [Transformers](https://nn.labml.ai/transformers/index.html)
* [Multi-headed attention](https://nn.labml.ai/transformers/mha.html)
* [Triton Flash Attention](https://nn.labml.ai/transformers/flash/index.html)
* [Transformer building blocks](https://nn.labml.ai/transformers/models.html)
* [Transformer XL](https://nn.labml.ai/transformers/xl/index.html)
* [Relative multi-headed attention](https://nn.labml.ai/transformers/xl/relative_mha.html)
* [Rotary Positional Embeddings](https://nn.labml.ai/transformers/rope/index.html)
* [Attention with Linear Biases (ALiBi)](https://nn.labml.ai/transformers/alibi/index.html)
* [RETRO](https://nn.labml.ai/transformers/retro/index.html)
* [Compressive Transformer](https://nn.labml.ai/transformers/compressive/index.html)
* [GPT Architecture](https://nn.labml.ai/transformers/gpt/index.html)
* [GLU Variants](https://nn.labml.ai/transformers/glu_variants/simple.html)
* [kNN-LM: Generalization through Memorization](https://nn.labml.ai/transformers/knn)
* [Feedback Transformer](https://nn.labml.ai/transformers/feedback/index.html)
* [Switch Transformer](https://nn.labml.ai/transformers/switch/index.html)
* [Fast Weights Transformer](https://nn.labml.ai/transformers/fast_weights/index.html)
* [FNet](https://nn.labml.ai/transformers/fnet/index.html)
* [Attention Free Transformer](https://nn.labml.ai/transformers/aft/index.html)
* [Masked Language Model](https://nn.labml.ai/transformers/mlm/index.html)
* [MLP-Mixer: An all-MLP Architecture for Vision](https://nn.labml.ai/transformers/mlp_mixer/index.html)
* [Pay Attention to MLPs (gMLP)](https://nn.labml.ai/transformers/gmlp/index.html)
* [Vision Transformer (ViT)](https://nn.labml.ai/transformers/vit/index.html)
* [Primer EZ](https://nn.labml.ai/transformers/primer_ez/index.html)
* [Hourglass](https://nn.labml.ai/transformers/hour_glass/index.html)
#### ✨ [Low-Rank Adaptation (LoRA)](https://nn.labml.ai/lora/index.html)
#### ✨ [Eleuther GPT-NeoX](https://nn.labml.ai/neox/index.html)
* [Generate on a 48GB GPU](https://nn.labml.ai/neox/samples/generate.html)
* [Finetune on two 48GB GPUs](https://nn.labml.ai/neox/samples/finetune.html)
* [LLM.int8()](https://nn.labml.ai/neox/utils/llm_int8.html)
#### ✨ [Diffusion models](https://nn.labml.ai/diffusion/index.html)
* [Denoising Diffusion Probabilistic Models (DDPM)](https://nn.labml.ai/diffusion/ddpm/index.html)
* [Denoising Diffusion Implicit Models (DDIM)](https://nn.labml.ai/diffusion/stable_diffusion/sampler/ddim.html)
* [Latent Diffusion Models](https://nn.labml.ai/diffusion/stable_diffusion/latent_diffusion.html)
* [Stable Diffusion](https://nn.labml.ai/diffusion/stable_diffusion/index.html)
#### ✨ [Generative Adversarial Networks](https://nn.labml.ai/gan/index.html)
* [Original GAN](https://nn.labml.ai/gan/original/index.html)
* [GAN with deep convolutional network](https://nn.labml.ai/gan/dcgan/index.html)
* [Cycle GAN](https://nn.labml.ai/gan/cycle_gan/index.html)
* [Wasserstein GAN](https://nn.labml.ai/gan/wasserstein/index.html)
* [Wasserstein GAN with Gradient Penalty](https://nn.labml.ai/gan/wasserstein/gradient_penalty/index.html)
* [StyleGAN 2](https://nn.labml.ai/gan/stylegan/index.html)
#### ✨ [Recurrent Highway Networks](https://nn.labml.ai/recurrent_highway_networks/index.html)
#### ✨ [LSTM](https://nn.labml.ai/lstm/index.html)
#### ✨ [HyperNetworks - HyperLSTM](https://nn.labml.ai/hypernetworks/hyper_lstm.html)
#### ✨ [ResNet](https://nn.labml.ai/resnet/index.html)
#### ✨ [ConvMixer](https://nn.labml.ai/conv_mixer/index.html)
#### ✨ [Capsule Networks](https://nn.labml.ai/capsule_networks/index.html)
#### ✨ [U-Net](https://nn.labml.ai/unet/index.html)
#### ✨ [Sketch RNN](https://nn.labml.ai/sketch_rnn/index.html)
#### ✨ Graph Neural Networks
* [Graph Attention Networks (GAT)](https://nn.labml.ai/graphs/gat/index.html)
* [Graph Attention Networks v2 (GATv2)](https://nn.labml.ai/graphs/gatv2/index.html)
#### ✨ [Counterfactual Regret Minimization (CFR)](https://nn.labml.ai/cfr/index.html)
Solving games with incomplete information such as poker with CFR.
* [Kuhn Poker](https://nn.labml.ai/cfr/kuhn/index.html)
#### ✨ [Reinforcement Learning](https://nn.labml.ai/rl/index.html)
* [Proximal Policy Optimization](https://nn.labml.ai/rl/ppo/index.html) with
[Generalized Advantage Estimation](https://nn.labml.ai/rl/ppo/gae.html)
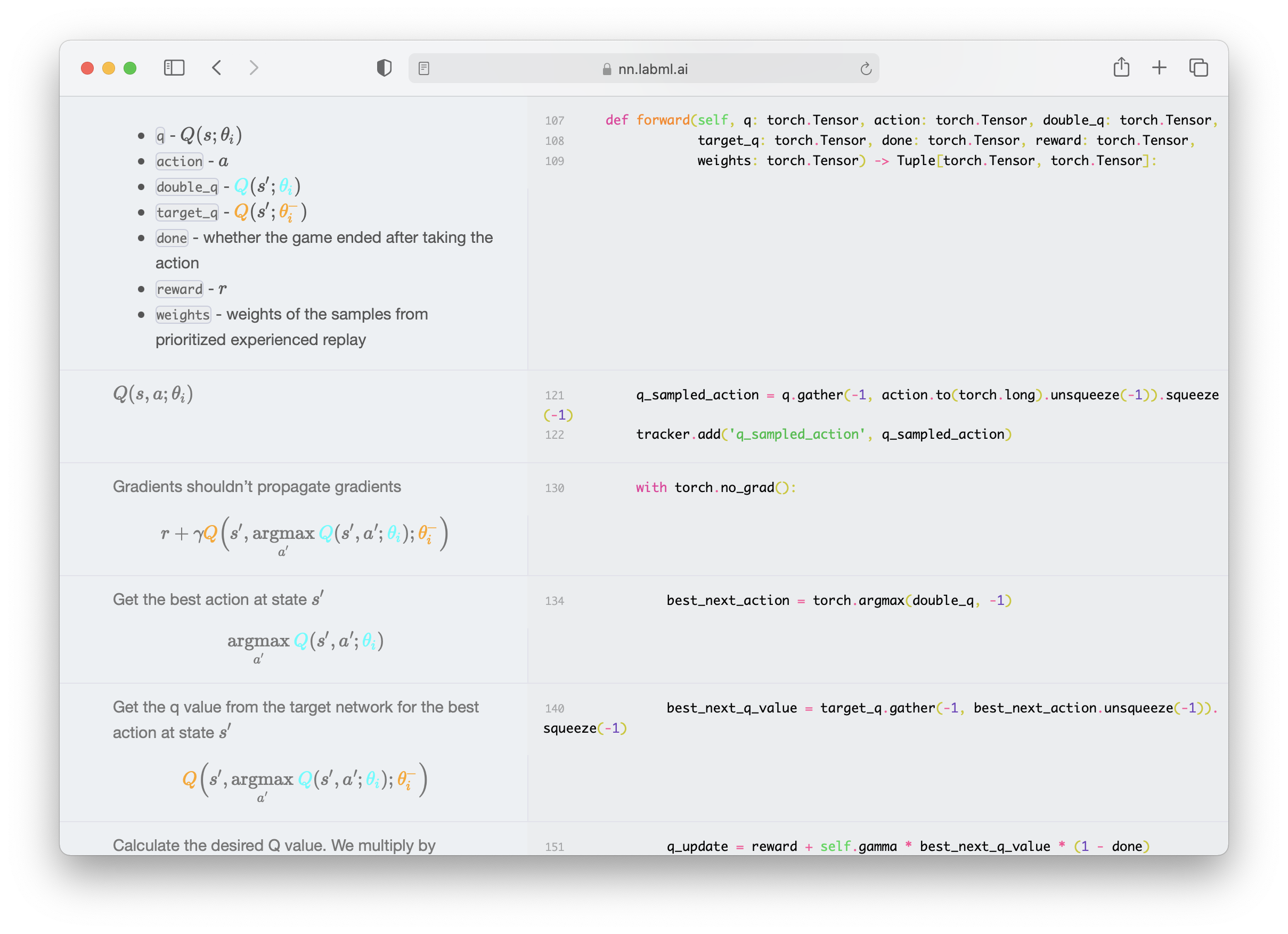
* [Deep Q Networks](https://nn.labml.ai/rl/dqn/index.html) with
with [Dueling Network](https://nn.labml.ai/rl/dqn/model.html),
[Prioritized Replay](https://nn.labml.ai/rl/dqn/replay_buffer.html)
and Double Q Network.
#### ✨ [Optimizers](https://nn.labml.ai/optimizers/index.html)
* [Adam](https://nn.labml.ai/optimizers/adam.html)
* [AMSGrad](https://nn.labml.ai/optimizers/amsgrad.html)
* [Adam Optimizer with warmup](https://nn.labml.ai/optimizers/adam_warmup.html)
* [Noam Optimizer](https://nn.labml.ai/optimizers/noam.html)
* [Rectified Adam Optimizer](https://nn.labml.ai/optimizers/radam.html)
* [AdaBelief Optimizer](https://nn.labml.ai/optimizers/ada_belief.html)
* [Sophia-G Optimizer](https://nn.labml.ai/optimizers/sophia.html)
#### ✨ [Normalization Layers](https://nn.labml.ai/normalization/index.html)
* [Batch Normalization](https://nn.labml.ai/normalization/batch_norm/index.html)
* [Layer Normalization](https://nn.labml.ai/normalization/layer_norm/index.html)
* [Instance Normalization](https://nn.labml.ai/normalization/instance_norm/index.html)
* [Group Normalization](https://nn.labml.ai/normalization/group_norm/index.html)
* [Weight Standardization](https://nn.labml.ai/normalization/weight_standardization/index.html)
* [Batch-Channel Normalization](https://nn.labml.ai/normalization/batch_channel_norm/index.html)
* [DeepNorm](https://nn.labml.ai/normalization/deep_norm/index.html)
#### ✨ [Distillation](https://nn.labml.ai/distillation/index.html)
#### ✨ [Adaptive Computation](https://nn.labml.ai/adaptive_computation/index.html)
* [PonderNet](https://nn.labml.ai/adaptive_computation/ponder_net/index.html)
#### ✨ [Uncertainty](https://nn.labml.ai/uncertainty/index.html)
* [Evidential Deep Learning to Quantify Classification Uncertainty](https://nn.labml.ai/uncertainty/evidence/index.html)
#### ✨ [Activations](https://nn.labml.ai/activations/index.html)
* [Fuzzy Tiling Activations](https://nn.labml.ai/activations/fta/index.html)
#### ✨ [Langauge Model Sampling Techniques](https://nn.labml.ai/sampling/index.html)
* [Greedy Sampling](https://nn.labml.ai/sampling/greedy.html)
* [Temperature Sampling](https://nn.labml.ai/sampling/temperature.html)
* [Top-k Sampling](https://nn.labml.ai/sampling/top_k.html)
* [Nucleus Sampling](https://nn.labml.ai/sampling/nucleus.html)
#### ✨ [Scalable Training/Inference](https://nn.labml.ai/scaling/index.html)
* [Zero3 memory optimizations](https://nn.labml.ai/scaling/zero3/index.html)
### Installation
```bash
pip install labml-nn
```
Raw data
{
"_id": null,
"home_page": "https://github.com/labmlai/annotated_deep_learning_paper_implementations",
"name": "labml-nn",
"maintainer": null,
"docs_url": null,
"requires_python": null,
"maintainer_email": null,
"keywords": "machine learning",
"author": "Varuna Jayasiri, Nipun Wijerathne",
"author_email": "vpjayasiri@gmail.com, hnipun@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/07/e6/4f9eeb84fb5a37d5efa7ae637e337f12e3e59acf3359ea2d0985dc874740/labml_nn-0.5.1.tar.gz",
"platform": null,
"description": "[](https://twitter.com/labmlai)\n\n# [labml.ai Deep Learning Paper Implementations](https://nn.labml.ai/index.html)\n\nThis is a collection of simple PyTorch implementations of\nneural networks and related algorithms.\nThese implementations are documented with explanations,\n\n[The website](https://nn.labml.ai/index.html)\nrenders these as side-by-side formatted notes.\nWe believe these would help you understand these algorithms better.\n\n\n\nWe are actively maintaining this repo and adding new \nimplementations almost weekly.\n[](https://twitter.com/labmlai) for updates.\n\n## Paper Implementations\n\n#### \u2728 [Transformers](https://nn.labml.ai/transformers/index.html)\n\n* [Multi-headed attention](https://nn.labml.ai/transformers/mha.html)\n* [Triton Flash Attention](https://nn.labml.ai/transformers/flash/index.html)\n* [Transformer building blocks](https://nn.labml.ai/transformers/models.html) \n* [Transformer XL](https://nn.labml.ai/transformers/xl/index.html)\n * [Relative multi-headed attention](https://nn.labml.ai/transformers/xl/relative_mha.html)\n* [Rotary Positional Embeddings](https://nn.labml.ai/transformers/rope/index.html)\n* [Attention with Linear Biases (ALiBi)](https://nn.labml.ai/transformers/alibi/index.html)\n* [RETRO](https://nn.labml.ai/transformers/retro/index.html)\n* [Compressive Transformer](https://nn.labml.ai/transformers/compressive/index.html)\n* [GPT Architecture](https://nn.labml.ai/transformers/gpt/index.html)\n* [GLU Variants](https://nn.labml.ai/transformers/glu_variants/simple.html)\n* [kNN-LM: Generalization through Memorization](https://nn.labml.ai/transformers/knn)\n* [Feedback Transformer](https://nn.labml.ai/transformers/feedback/index.html)\n* [Switch Transformer](https://nn.labml.ai/transformers/switch/index.html)\n* [Fast Weights Transformer](https://nn.labml.ai/transformers/fast_weights/index.html)\n* [FNet](https://nn.labml.ai/transformers/fnet/index.html)\n* [Attention Free Transformer](https://nn.labml.ai/transformers/aft/index.html)\n* [Masked Language Model](https://nn.labml.ai/transformers/mlm/index.html)\n* [MLP-Mixer: An all-MLP Architecture for Vision](https://nn.labml.ai/transformers/mlp_mixer/index.html)\n* [Pay Attention to MLPs (gMLP)](https://nn.labml.ai/transformers/gmlp/index.html)\n* [Vision Transformer (ViT)](https://nn.labml.ai/transformers/vit/index.html)\n* [Primer EZ](https://nn.labml.ai/transformers/primer_ez/index.html)\n* [Hourglass](https://nn.labml.ai/transformers/hour_glass/index.html)\n\n#### \u2728 [Low-Rank Adaptation (LoRA)](https://nn.labml.ai/lora/index.html)\n\n#### \u2728 [Eleuther GPT-NeoX](https://nn.labml.ai/neox/index.html)\n* [Generate on a 48GB GPU](https://nn.labml.ai/neox/samples/generate.html)\n* [Finetune on two 48GB GPUs](https://nn.labml.ai/neox/samples/finetune.html)\n* [LLM.int8()](https://nn.labml.ai/neox/utils/llm_int8.html)\n\n#### \u2728 [Diffusion models](https://nn.labml.ai/diffusion/index.html)\n\n* [Denoising Diffusion Probabilistic Models (DDPM)](https://nn.labml.ai/diffusion/ddpm/index.html)\n* [Denoising Diffusion Implicit Models (DDIM)](https://nn.labml.ai/diffusion/stable_diffusion/sampler/ddim.html)\n* [Latent Diffusion Models](https://nn.labml.ai/diffusion/stable_diffusion/latent_diffusion.html)\n* [Stable Diffusion](https://nn.labml.ai/diffusion/stable_diffusion/index.html)\n\n#### \u2728 [Generative Adversarial Networks](https://nn.labml.ai/gan/index.html)\n* [Original GAN](https://nn.labml.ai/gan/original/index.html)\n* [GAN with deep convolutional network](https://nn.labml.ai/gan/dcgan/index.html)\n* [Cycle GAN](https://nn.labml.ai/gan/cycle_gan/index.html)\n* [Wasserstein GAN](https://nn.labml.ai/gan/wasserstein/index.html)\n* [Wasserstein GAN with Gradient Penalty](https://nn.labml.ai/gan/wasserstein/gradient_penalty/index.html)\n* [StyleGAN 2](https://nn.labml.ai/gan/stylegan/index.html)\n\n#### \u2728 [Recurrent Highway Networks](https://nn.labml.ai/recurrent_highway_networks/index.html)\n\n#### \u2728 [LSTM](https://nn.labml.ai/lstm/index.html)\n\n#### \u2728 [HyperNetworks - HyperLSTM](https://nn.labml.ai/hypernetworks/hyper_lstm.html)\n\n#### \u2728 [ResNet](https://nn.labml.ai/resnet/index.html)\n\n#### \u2728 [ConvMixer](https://nn.labml.ai/conv_mixer/index.html)\n\n#### \u2728 [Capsule Networks](https://nn.labml.ai/capsule_networks/index.html)\n\n#### \u2728 [U-Net](https://nn.labml.ai/unet/index.html)\n\n#### \u2728 [Sketch RNN](https://nn.labml.ai/sketch_rnn/index.html)\n\n#### \u2728 Graph Neural Networks\n\n* [Graph Attention Networks (GAT)](https://nn.labml.ai/graphs/gat/index.html)\n* [Graph Attention Networks v2 (GATv2)](https://nn.labml.ai/graphs/gatv2/index.html)\n\n#### \u2728 [Counterfactual Regret Minimization (CFR)](https://nn.labml.ai/cfr/index.html)\n\nSolving games with incomplete information such as poker with CFR.\n\n* [Kuhn Poker](https://nn.labml.ai/cfr/kuhn/index.html)\n\n#### \u2728 [Reinforcement Learning](https://nn.labml.ai/rl/index.html)\n* [Proximal Policy Optimization](https://nn.labml.ai/rl/ppo/index.html) with\n [Generalized Advantage Estimation](https://nn.labml.ai/rl/ppo/gae.html)\n* [Deep Q Networks](https://nn.labml.ai/rl/dqn/index.html) with\n with [Dueling Network](https://nn.labml.ai/rl/dqn/model.html),\n [Prioritized Replay](https://nn.labml.ai/rl/dqn/replay_buffer.html)\n and Double Q Network.\n\n#### \u2728 [Optimizers](https://nn.labml.ai/optimizers/index.html)\n* [Adam](https://nn.labml.ai/optimizers/adam.html)\n* [AMSGrad](https://nn.labml.ai/optimizers/amsgrad.html)\n* [Adam Optimizer with warmup](https://nn.labml.ai/optimizers/adam_warmup.html)\n* [Noam Optimizer](https://nn.labml.ai/optimizers/noam.html)\n* [Rectified Adam Optimizer](https://nn.labml.ai/optimizers/radam.html)\n* [AdaBelief Optimizer](https://nn.labml.ai/optimizers/ada_belief.html)\n* [Sophia-G Optimizer](https://nn.labml.ai/optimizers/sophia.html)\n\n#### \u2728 [Normalization Layers](https://nn.labml.ai/normalization/index.html)\n* [Batch Normalization](https://nn.labml.ai/normalization/batch_norm/index.html)\n* [Layer Normalization](https://nn.labml.ai/normalization/layer_norm/index.html)\n* [Instance Normalization](https://nn.labml.ai/normalization/instance_norm/index.html)\n* [Group Normalization](https://nn.labml.ai/normalization/group_norm/index.html)\n* [Weight Standardization](https://nn.labml.ai/normalization/weight_standardization/index.html)\n* [Batch-Channel Normalization](https://nn.labml.ai/normalization/batch_channel_norm/index.html)\n* [DeepNorm](https://nn.labml.ai/normalization/deep_norm/index.html)\n\n#### \u2728 [Distillation](https://nn.labml.ai/distillation/index.html)\n\n#### \u2728 [Adaptive Computation](https://nn.labml.ai/adaptive_computation/index.html)\n\n* [PonderNet](https://nn.labml.ai/adaptive_computation/ponder_net/index.html)\n\n#### \u2728 [Uncertainty](https://nn.labml.ai/uncertainty/index.html)\n\n* [Evidential Deep Learning to Quantify Classification Uncertainty](https://nn.labml.ai/uncertainty/evidence/index.html)\n\n#### \u2728 [Activations](https://nn.labml.ai/activations/index.html)\n\n* [Fuzzy Tiling Activations](https://nn.labml.ai/activations/fta/index.html)\n\n#### \u2728 [Langauge Model Sampling Techniques](https://nn.labml.ai/sampling/index.html)\n* [Greedy Sampling](https://nn.labml.ai/sampling/greedy.html)\n* [Temperature Sampling](https://nn.labml.ai/sampling/temperature.html)\n* [Top-k Sampling](https://nn.labml.ai/sampling/top_k.html)\n* [Nucleus Sampling](https://nn.labml.ai/sampling/nucleus.html)\n\n#### \u2728 [Scalable Training/Inference](https://nn.labml.ai/scaling/index.html)\n* [Zero3 memory optimizations](https://nn.labml.ai/scaling/zero3/index.html)\n\n### Installation\n\n```bash\npip install labml-nn\n```\n",
"bugtrack_url": null,
"license": null,
"summary": "\ud83e\uddd1\u200d\ud83c\udfeb Implementations/tutorials of deep learning papers with side-by-side notes \ud83d\udcdd; including transformers (original, xl, switch, feedback, vit), optimizers (adam, radam, adabelief), gans(dcgan, cyclegan, stylegan2), \ud83c\udfae reinforcement learning (ppo, dqn), capsnet, distillation, diffusion, etc. \ud83e\udde0",
"version": "0.5.1",
"project_urls": {
"Documentation": "https://nn.labml.ai",
"Homepage": "https://github.com/labmlai/annotated_deep_learning_paper_implementations"
},
"split_keywords": [
"machine",
"learning"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "a1ed058a18295819037c4ae8ad2b273aa287d4afacc324a883e3ed95ae890bfc",
"md5": "2bda829cd68f4ce337d28b14dc10d528",
"sha256": "ba6b6d4efb2590636f237aa6204ffe789b3ec484088226248890393e225a5761"
},
"downloads": -1,
"filename": "labml_nn-0.5.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "2bda829cd68f4ce337d28b14dc10d528",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": null,
"size": 461912,
"upload_time": "2025-08-08T14:31:01",
"upload_time_iso_8601": "2025-08-08T14:31:01.970664Z",
"url": "https://files.pythonhosted.org/packages/a1/ed/058a18295819037c4ae8ad2b273aa287d4afacc324a883e3ed95ae890bfc/labml_nn-0.5.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "07e64f9eeb84fb5a37d5efa7ae637e337f12e3e59acf3359ea2d0985dc874740",
"md5": "1094f88ebcf219f9e83d0e43765b6ef7",
"sha256": "14a23a126e3da62ddb38a2a4e3fd082581b42ab4b82f270882e0a6378be1546b"
},
"downloads": -1,
"filename": "labml_nn-0.5.1.tar.gz",
"has_sig": false,
"md5_digest": "1094f88ebcf219f9e83d0e43765b6ef7",
"packagetype": "sdist",
"python_version": "source",
"requires_python": null,
"size": 334201,
"upload_time": "2025-08-08T14:31:04",
"upload_time_iso_8601": "2025-08-08T14:31:04.070959Z",
"url": "https://files.pythonhosted.org/packages/07/e6/4f9eeb84fb5a37d5efa7ae637e337f12e3e59acf3359ea2d0985dc874740/labml_nn-0.5.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-08-08 14:31:04",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "labmlai",
"github_project": "annotated_deep_learning_paper_implementations",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"requirements": [
{
"name": "torch",
"specs": [
[
">=",
"1.10"
]
]
},
{
"name": "torchvision",
"specs": [
[
">=",
"0.11"
]
]
},
{
"name": "torchtext",
"specs": [
[
">=",
"0.11"
]
]
},
{
"name": "labml",
"specs": [
[
">=",
"0.4.147"
]
]
},
{
"name": "labml-helpers",
"specs": [
[
">=",
"0.4.84"
]
]
},
{
"name": "numpy",
"specs": [
[
">=",
"1.19"
]
]
},
{
"name": "matplotlib",
"specs": [
[
">=",
"3.0.3"
]
]
},
{
"name": "einops",
"specs": [
[
">=",
"0.3.0"
]
]
},
{
"name": "gym",
"specs": []
},
{
"name": "opencv-python",
"specs": []
},
{
"name": "Pillow",
"specs": [
[
">=",
"6.2.1"
]
]
},
{
"name": "faiss",
"specs": []
}
],
"lcname": "labml-nn"
}
