<div align="center">
<a href="https://rapidfire.ai">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/RapidFireAI/rapidfireai/main/images/RapidFire-logo-for-dark-theme.svg">
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/RapidFireAI/rapidfireai/main/images/RapidFire-logo-for-light-theme.svg">
<img alt="RapidFire AI" src="https://raw.githubusercontent.com/RapidFireAI/rapidfireai/main/images/RapidFire-logo-for-light-theme.svg">
</picture>
</a>
</div>
[](https://pypi.org/project/rapidfireai/)
# RapidFire AI
Rapid experimentation for easier, faster, and more impactful fine-tuning and post-training for LLMs and other DL models — delivering 16–24× higher throughput without extra GPUs.
## Overview
RapidFire AI is a new experiment execution framework that transforms your LLM customization experimentation from slow, sequential processes into rapid, intelligent workflows with hyperparallelized training, dynamic real-time experiment control, and automatic multi-GPU system orchestration.
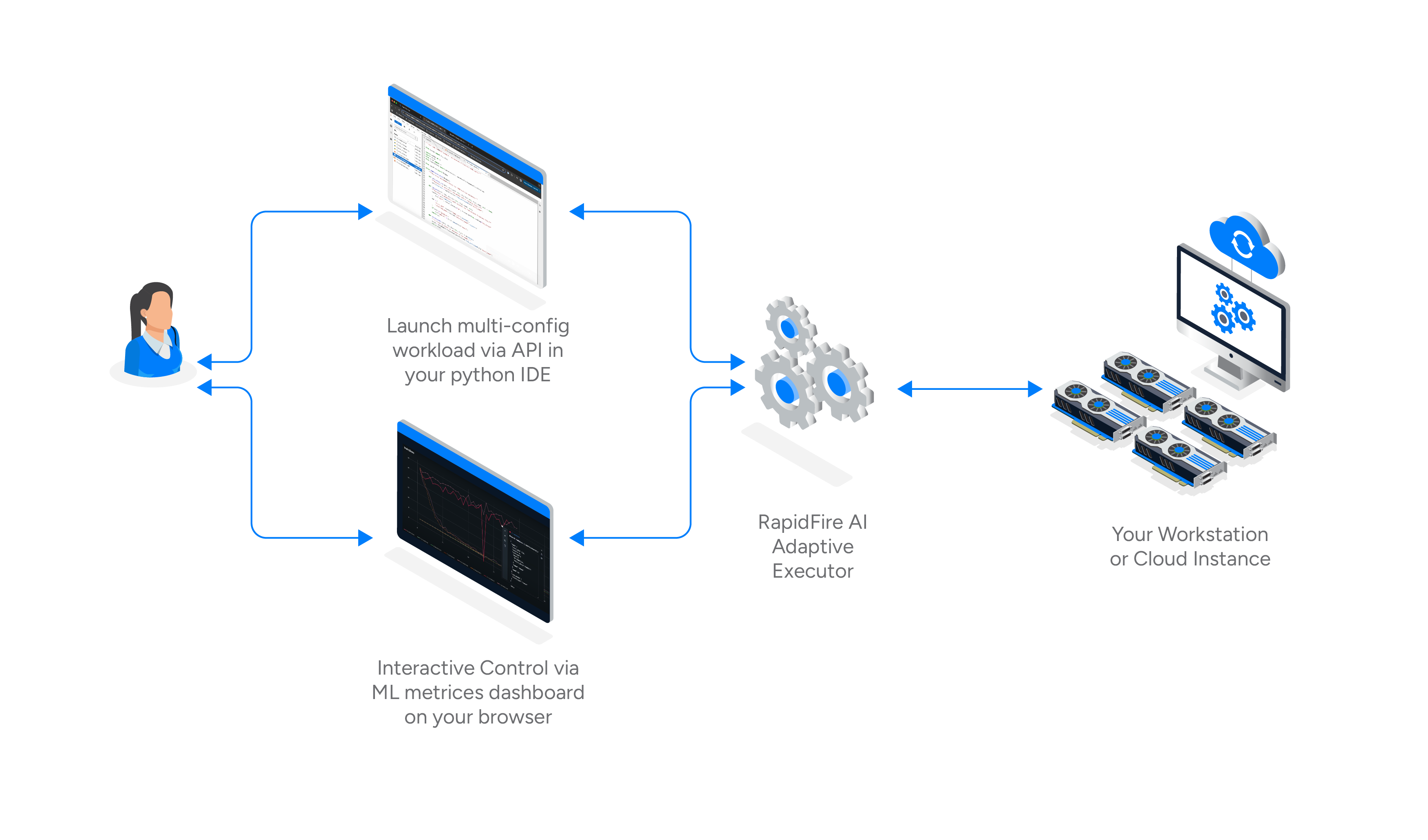
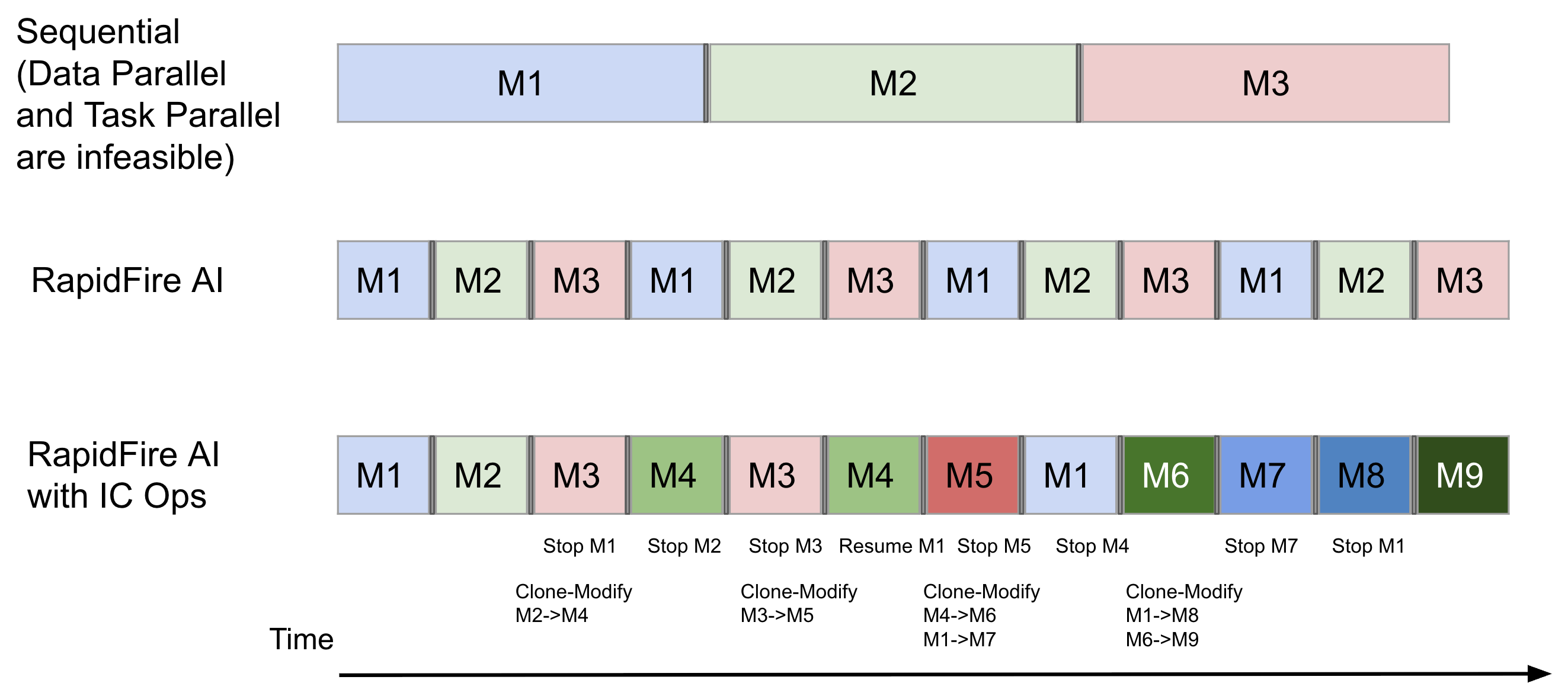
RapidFire AI’s adaptive execution engine enables interruptible, chunk-based scheduling so you can compare many configurations concurrently—even on a single GPU—with dynamic real-time control over runs.
- **Hyperparallelized Execution**: Higher throughput, simultaneous, data chunk-at-a-time training to show side-by-side differences.
- **Interactive control (IC Ops)**: Stop, Resume, Clone-Modify, and optionally warm start runs in real-time from the dashboard.
- **Automatic Optimization**: Intelligent single and multi-GPU orchestration to optimze utilization with minimal overhead.
For additional context, see the overview: [RapidFire AI Overview](https://oss-docs.rapidfire.ai/en/latest/overview.html)
## Getting Started
### Prerequisites
- [NVIDIA GPU using the 7.x or 8.x Compute Capability](https://developer.nvidia.com/cuda-gpus)
- [NVIDIA CUDA Toolkit 11.8+](https://developer.nvidia.com/cuda-toolkit-archive)
- [Python 3.12.x](https://www.python.org/downloads/)
- [PyTorch 2.7.1+](https://pytorch.org/get-started/previous-versions/) with corresponding forward compatible prebuilt CUDA binaries
### Installation/Starting
```bash
python3 -m venv .venv
source .venv/bin/activate
# from pypi
pip install rapidfireai
# install specific dependencies and initialize rapidfire
# Optionally set RF_TUTORIAL_PATH environment variable to sepecify
# alternate location for copying tutorial notebooks to
rapidfireai init
# start the rapidfire server
# For Google Colab run:
# export RF_TRACKING_BACKEND=tensorboard
# rapidfireai start --colab
# For standalone run:
rapidfireai start
# open up example notebook and start experiment
```
### Running tutorial notebooks
```bash
source .venv/bin/activate
# from replace <your_token> with your hugging face token
# https://huggingface.co/docs/hub/en/security-tokens
pip install "huggingface-hub[cli]"
hf auth login --token <your_token>
# Due to current issue: https://github.com/huggingface/xet-core/issues/527
pip uninstall -y hf-xet
# open up example notebook from ./tutorial_notebooks and start experiment
```
### Troubleshooting
For a quick system diagnostics report (Python env, relevant packages, GPU/CUDA, and key environment variables), run:
```bash
rapidfireai doctor
```
If you encounter port conflicts, you can kill existing processes:
```bash
lsof -t -i:5002 | xargs kill -9 # mlflow
lsof -t -i:8081 | xargs kill -9 # dispatcher
lsof -t -i:3000 | xargs kill -9 # frontend server
```
## Documentation
Browse or reference the full documentation, example use case tutorials, all API details, dashboard details, and more in the [RapidFire AI Documentation](https://oss-docs.rapidfire.ai).
## Key Features
### MLflow Integration
Full MLflow support for experiment tracking and metrics visualization. A named RapidFire AI experiment corresponds to an MLflow experiment for comprehensive governance
### Interactive Control Operations (IC Ops)
First-of-its-kind dynamic real-time control over runs in flight. Can be invoked through the dashboard:
- Stop active runs; puts them in a dormant state
- Resume stopped runs; makes them active again
- Clone and modify existing runs, with or without warm starting from parent’s weights
- Delete unwanted or failed runs
### Multi-GPU Support
The Scheduler automatically handles multiple GPUs on the machine and divides resources across all running configs for optimal resource utilization.
### Search and AutoML Support
Built-in procedures for searching over configuration knob combinations, including Grid Search and Random Search. Easy to integrate with AutoML procedures. Native support for some popular AutoML procedures and customized automation of IC Ops coming soon.
## Directory Structure
```text
rapidfireai/
├── automl/ # Search and AutoML algorithms for knob tuning
├── backend/ # Core backend components (controller, scheduler, worker)
├── db/ # Database interface and SQLite operations
├── dispatcher/ # Flask-based web API for UI communication
├── frontend/ # Frontend components (dashboard, IC Ops implementation)
├── ml/ # ML training utilities and trainer classes
├── utils/ # Utility functions and helper modules
└── experiment.py # Main experiment lifecycle management
```
## Architecture
RapidFire AI adopts a microservices-inspired loosely coupled distributed architecture with:
- **Dispatcher**: Web API layer for UI communication
- **Database**: SQLite for state persistence
- **Controller**: Central orchestrator running in user process
- **Workers**: GPU-based training processes
- **Dashboard**: Experiment tracking and visualization dashboard
This design enables efficient resource utilization while providing a seamless user experience for AI experimentation.
## Components
### Dispatcher
The dispatcher provides a REST API interface for the web UI. It can be run via Flask as a single app or via Gunicorn to have it load balanced. Handles interactive control features and displays the current state of the runs in the experiment.
### Database
Uses SQLite for persistent storage of metadata of experiments, runs, and artifacts. The Controller also uses it to talk with Workers on scheduling state. A clean asynchronous interface for all DB operations, including experiment lifecycle management and run tracking.
### Controller
Runs as part of the user’s console or Notebook process. Orchestrates the entire training lifecycle including model creation, worker management, and scheduling. The `run_fit` logic handles sample preprocessing, model creation for given knob configurations, worker initialization, and continuous monitoring of training progress across distributed workers.
### Worker
Handles the actual model training and inference on the GPUs. Workers poll the Database for tasks, load dataset chunks, and execute training runs with checkpointing and progress reporting. Currently expects any given model for given batch size to fit on a single GPU.
### Experiment
Manages the complete experiment lifecycle, including creation, naming conventions, and cleanup. Experiments are automatically named with unique suffixes if conflicts exist, and all experiment metadata is tracked in the Database. An experiment's running tasks are automatically cancelled when the process ends abruptly.
### Dashboard
A fork of MLflow that enables full tracking and visualization of all experiments and runs. It features a new panel for Interactive Control Ops that can be performed on any active runs.
## Developing with RapidFire AI
### Development prerequisites
- Python 3.12.x
- Git
- Ubuntu/Debian system (for apt package manager)
```bash
# Run these commands one after the other on a fresh Ubuntu machine
# install dependencies
sudo apt update -y
# clone the repository
git clone https://github.com/RapidFireAI/rapidfireai.git
# navigate to the repository
cd ./rapidfireai
# install basic dependencies
sudo apt install -y python3.12-venv
python3 -m venv .venv
source .venv/bin/activate
pip3 install ipykernel
pip3 install jupyter
pip3 install "huggingface-hub[cli]"
export PATH="$HOME/.local/bin:$PATH"
hf auth login --token <your_token>
# Due to current issue: https://github.com/huggingface/xet-core/issues/527
pip uninstall -y hf-xet
# checkout the main branch
git checkout main
# install the repository as a python package
pip3 install -r requirements.txt
# install node
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash - && sudo apt-get install -y nodejs
# Install correct version of vllm and flash-attn
# uv pip install vllm=0.10.1.1 --torch-backend=cu126 or cu118
# uv pip install flash-attn==1.0.9 --no-build-isoloation or 2.8.3
# if running into node versioning errors, remove the previous version of node then run the lines above again
sudo apt-get remove --purge nodejs libnode-dev libnode72 npm
sudo apt autoremove --purge
# check installations
node -v # 22.x
# still inside venv, run the start script to begin all 3 servers
chmod +x ./rapidfireai/start_dev.sh
./rapidfireai/start_dev.sh start
# run the notebook from within your IDE
# make sure the notebook is running in the .venv virtual environment
# head to settings in Cursor/VSCode and search for venv and add the path - $HOME/rapidfireai/.venv
# we cannot run a Jupyter notebook directly since there are restrictions on Jupyter being able to create child processes
# VSCode can port-forward localhost:3000 where the rf-frontend server will be running
# for port clash issues -
lsof -t -i:8081 | xargs kill -9 # dispatcher
lsof -t -i:5002 | xargs kill -9 # mlflow
lsof -t -i:3000 | xargs kill -9 # frontend
```
## Community & Governance
- Docs: [oss-docs.rapidfire.ai](https://oss-docs.rapidfire.ai)
- Discord: [Join our Discord](https://discord.gg/6vSTtncKNN)
- Contributing: [`CONTRIBUTING.md`](CONTRIBUTING.md)
- License: [`LICENSE`](LICENSE)
- Issues: use GitHub Issues for bug reports and feature requests
Raw data
{
"_id": null,
"home_page": null,
"name": "rapidfireai",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.12",
"maintainer_email": null,
"keywords": "ai, rapidfire, rapidfireai, llm, deep-learning, artificial-intelligence, machine-learning, mlflow, experiment-tracking",
"author": null,
"author_email": "\"RapidFire AI Inc.\" <support@rapidfire.ai>",
"download_url": "https://files.pythonhosted.org/packages/30/90/c90a8ad2d78102bf12444ad7064c896ff9d8f86f1959aa64c57e93742301/rapidfireai-0.11.1.tar.gz",
"platform": null,
"description": "\n<div align=\"center\">\n\n<a href=\"https://rapidfire.ai\"> \n <picture>\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://raw.githubusercontent.com/RapidFireAI/rapidfireai/main/images/RapidFire-logo-for-dark-theme.svg\">\n <source media=\"(prefers-color-scheme: light)\" srcset=\"https://raw.githubusercontent.com/RapidFireAI/rapidfireai/main/images/RapidFire-logo-for-light-theme.svg\">\n <img alt=\"RapidFire AI\" src=\"https://raw.githubusercontent.com/RapidFireAI/rapidfireai/main/images/RapidFire-logo-for-light-theme.svg\">\n </picture>\n</a>\n\n\n</div>\n\n[](https://pypi.org/project/rapidfireai/)\n\n# RapidFire AI\n\nRapid experimentation for easier, faster, and more impactful fine-tuning and post-training for LLMs and other DL models \u2014 delivering 16\u201324\u00d7 higher throughput without extra GPUs.\n\n## Overview\n\nRapidFire AI is a new experiment execution framework that transforms your LLM customization experimentation from slow, sequential processes into rapid, intelligent workflows with hyperparallelized training, dynamic real-time experiment control, and automatic multi-GPU system orchestration.\n\n\n\nRapidFire AI\u2019s adaptive execution engine enables interruptible, chunk-based scheduling so you can compare many configurations concurrently\u2014even on a single GPU\u2014with dynamic real-time control over runs.\n\n- **Hyperparallelized Execution**: Higher throughput, simultaneous, data chunk-at-a-time training to show side-by-side differences.\n- **Interactive control (IC Ops)**: Stop, Resume, Clone-Modify, and optionally warm start runs in real-time from the dashboard.\n- **Automatic Optimization**: Intelligent single and multi-GPU orchestration to optimze utilization with minimal overhead.\n\n\n\nFor additional context, see the overview: [RapidFire AI Overview](https://oss-docs.rapidfire.ai/en/latest/overview.html)\n\n## Getting Started\n\n### Prerequisites\n\n- [NVIDIA GPU using the 7.x or 8.x Compute Capability](https://developer.nvidia.com/cuda-gpus)\n- [NVIDIA CUDA Toolkit 11.8+](https://developer.nvidia.com/cuda-toolkit-archive)\n- [Python 3.12.x](https://www.python.org/downloads/)\n- [PyTorch 2.7.1+](https://pytorch.org/get-started/previous-versions/) with corresponding forward compatible prebuilt CUDA binaries\n\n### Installation/Starting\n\n```bash\npython3 -m venv .venv\nsource .venv/bin/activate\n\n# from pypi\npip install rapidfireai\n\n# install specific dependencies and initialize rapidfire\n# Optionally set RF_TUTORIAL_PATH environment variable to sepecify\n# alternate location for copying tutorial notebooks to\nrapidfireai init\n\n# start the rapidfire server\n# For Google Colab run:\n# export RF_TRACKING_BACKEND=tensorboard\n# rapidfireai start --colab\n# For standalone run:\nrapidfireai start\n\n# open up example notebook and start experiment\n```\n\n### Running tutorial notebooks\n\n```bash\nsource .venv/bin/activate\n\n# from replace <your_token> with your hugging face token\n# https://huggingface.co/docs/hub/en/security-tokens\npip install \"huggingface-hub[cli]\"\nhf auth login --token <your_token>\n\n# Due to current issue: https://github.com/huggingface/xet-core/issues/527\npip uninstall -y hf-xet\n\n# open up example notebook from ./tutorial_notebooks and start experiment\n```\n\n### Troubleshooting\n\nFor a quick system diagnostics report (Python env, relevant packages, GPU/CUDA, and key environment variables), run:\n\n```bash\nrapidfireai doctor\n```\n\nIf you encounter port conflicts, you can kill existing processes:\n\n```bash\nlsof -t -i:5002 | xargs kill -9 # mlflow\nlsof -t -i:8081 | xargs kill -9 # dispatcher\nlsof -t -i:3000 | xargs kill -9 # frontend server\n```\n\n## Documentation\n\nBrowse or reference the full documentation, example use case tutorials, all API details, dashboard details, and more in the [RapidFire AI Documentation](https://oss-docs.rapidfire.ai).\n\n## Key Features\n\n### MLflow Integration\n\nFull MLflow support for experiment tracking and metrics visualization. A named RapidFire AI experiment corresponds to an MLflow experiment for comprehensive governance\n\n### Interactive Control Operations (IC Ops)\n\nFirst-of-its-kind dynamic real-time control over runs in flight. Can be invoked through the dashboard:\n\n- Stop active runs; puts them in a dormant state\n- Resume stopped runs; makes them active again\n- Clone and modify existing runs, with or without warm starting from parent\u2019s weights\n- Delete unwanted or failed runs\n\n### Multi-GPU Support\n\nThe Scheduler automatically handles multiple GPUs on the machine and divides resources across all running configs for optimal resource utilization.\n\n### Search and AutoML Support\n\nBuilt-in procedures for searching over configuration knob combinations, including Grid Search and Random Search. Easy to integrate with AutoML procedures. Native support for some popular AutoML procedures and customized automation of IC Ops coming soon.\n\n## Directory Structure\n\n```text\nrapidfireai/\n\u251c\u2500\u2500 automl/ # Search and AutoML algorithms for knob tuning\n\u251c\u2500\u2500 backend/ # Core backend components (controller, scheduler, worker)\n\u251c\u2500\u2500 db/ # Database interface and SQLite operations\n\u251c\u2500\u2500 dispatcher/ # Flask-based web API for UI communication\n\u251c\u2500\u2500 frontend/ # Frontend components (dashboard, IC Ops implementation)\n\u251c\u2500\u2500 ml/ # ML training utilities and trainer classes\n\u251c\u2500\u2500 utils/ # Utility functions and helper modules\n\u2514\u2500\u2500 experiment.py # Main experiment lifecycle management\n```\n\n## Architecture\n\nRapidFire AI adopts a microservices-inspired loosely coupled distributed architecture with:\n\n- **Dispatcher**: Web API layer for UI communication\n- **Database**: SQLite for state persistence\n- **Controller**: Central orchestrator running in user process\n- **Workers**: GPU-based training processes\n- **Dashboard**: Experiment tracking and visualization dashboard\n\nThis design enables efficient resource utilization while providing a seamless user experience for AI experimentation.\n\n## Components\n\n### Dispatcher\n\nThe dispatcher provides a REST API interface for the web UI. It can be run via Flask as a single app or via Gunicorn to have it load balanced. Handles interactive control features and displays the current state of the runs in the experiment.\n\n### Database\n\nUses SQLite for persistent storage of metadata of experiments, runs, and artifacts. The Controller also uses it to talk with Workers on scheduling state. A clean asynchronous interface for all DB operations, including experiment lifecycle management and run tracking.\n\n### Controller\n\nRuns as part of the user\u2019s console or Notebook process. Orchestrates the entire training lifecycle including model creation, worker management, and scheduling. The `run_fit` logic handles sample preprocessing, model creation for given knob configurations, worker initialization, and continuous monitoring of training progress across distributed workers.\n\n### Worker\n\nHandles the actual model training and inference on the GPUs. Workers poll the Database for tasks, load dataset chunks, and execute training runs with checkpointing and progress reporting. Currently expects any given model for given batch size to fit on a single GPU.\n\n### Experiment\n\nManages the complete experiment lifecycle, including creation, naming conventions, and cleanup. Experiments are automatically named with unique suffixes if conflicts exist, and all experiment metadata is tracked in the Database. An experiment's running tasks are automatically cancelled when the process ends abruptly.\n\n### Dashboard\n\nA fork of MLflow that enables full tracking and visualization of all experiments and runs. It features a new panel for Interactive Control Ops that can be performed on any active runs.\n\n## Developing with RapidFire AI\n\n### Development prerequisites\n\n- Python 3.12.x\n- Git\n- Ubuntu/Debian system (for apt package manager)\n\n```bash\n# Run these commands one after the other on a fresh Ubuntu machine\n\n# install dependencies\nsudo apt update -y\n\n# clone the repository\ngit clone https://github.com/RapidFireAI/rapidfireai.git\n\n# navigate to the repository\ncd ./rapidfireai\n\n# install basic dependencies\nsudo apt install -y python3.12-venv\npython3 -m venv .venv\nsource .venv/bin/activate\npip3 install ipykernel\npip3 install jupyter\npip3 install \"huggingface-hub[cli]\"\nexport PATH=\"$HOME/.local/bin:$PATH\"\nhf auth login --token <your_token>\n\n# Due to current issue: https://github.com/huggingface/xet-core/issues/527\npip uninstall -y hf-xet\n\n# checkout the main branch\ngit checkout main\n\n# install the repository as a python package\npip3 install -r requirements.txt\n\n# install node\ncurl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash - && sudo apt-get install -y nodejs\n\n# Install correct version of vllm and flash-attn\n# uv pip install vllm=0.10.1.1 --torch-backend=cu126 or cu118\n# uv pip install flash-attn==1.0.9 --no-build-isoloation or 2.8.3\n\n# if running into node versioning errors, remove the previous version of node then run the lines above again\nsudo apt-get remove --purge nodejs libnode-dev libnode72 npm\nsudo apt autoremove --purge\n\n# check installations\nnode -v # 22.x\n\n# still inside venv, run the start script to begin all 3 servers\nchmod +x ./rapidfireai/start_dev.sh\n./rapidfireai/start_dev.sh start\n\n# run the notebook from within your IDE\n# make sure the notebook is running in the .venv virtual environment\n# head to settings in Cursor/VSCode and search for venv and add the path - $HOME/rapidfireai/.venv\n# we cannot run a Jupyter notebook directly since there are restrictions on Jupyter being able to create child processes\n\n# VSCode can port-forward localhost:3000 where the rf-frontend server will be running\n\n# for port clash issues -\nlsof -t -i:8081 | xargs kill -9 # dispatcher\nlsof -t -i:5002 | xargs kill -9 # mlflow\nlsof -t -i:3000 | xargs kill -9 # frontend\n```\n\n## Community & Governance\n\n- Docs: [oss-docs.rapidfire.ai](https://oss-docs.rapidfire.ai)\n- Discord: [Join our Discord](https://discord.gg/6vSTtncKNN)\n- Contributing: [`CONTRIBUTING.md`](CONTRIBUTING.md)\n- License: [`LICENSE`](LICENSE)\n- Issues: use GitHub Issues for bug reports and feature requests\n",
"bugtrack_url": null,
"license": "Apache-2.0",
"summary": "RapidFire AI: Rapid Experimentation Engine for Customizing LLMs",
"version": "0.11.1",
"project_urls": {
"Documentation": "https://oss-docs.rapidfire.ai",
"Homepage": "https://rapidfire.ai",
"Repository": "https://github.com/RapidFireAI/rapidfireai"
},
"split_keywords": [
"ai",
" rapidfire",
" rapidfireai",
" llm",
" deep-learning",
" artificial-intelligence",
" machine-learning",
" mlflow",
" experiment-tracking"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "7bab09a06ff27182356425cfc9cdb58c125dbb59c8f2da4205f019bf9cae5661",
"md5": "9897fdecbc5deb0f9644fddd9b587d2d",
"sha256": "1946f98a65e232f801ff819a3137ad2c4df57347cf5bc9f39b3dad587edd0dec"
},
"downloads": -1,
"filename": "rapidfireai-0.11.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "9897fdecbc5deb0f9644fddd9b587d2d",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.12",
"size": 30596628,
"upload_time": "2025-10-21T22:00:09",
"upload_time_iso_8601": "2025-10-21T22:00:09.532171Z",
"url": "https://files.pythonhosted.org/packages/7b/ab/09a06ff27182356425cfc9cdb58c125dbb59c8f2da4205f019bf9cae5661/rapidfireai-0.11.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "3090c90a8ad2d78102bf12444ad7064c896ff9d8f86f1959aa64c57e93742301",
"md5": "24e459f28549991b40936837ea6f1033",
"sha256": "3cc6e329b04a60b605ba21f265628c6f70c3874a22b78c8e0c6bda4ad74dbc9d"
},
"downloads": -1,
"filename": "rapidfireai-0.11.1.tar.gz",
"has_sig": false,
"md5_digest": "24e459f28549991b40936837ea6f1033",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.12",
"size": 30274438,
"upload_time": "2025-10-21T22:00:12",
"upload_time_iso_8601": "2025-10-21T22:00:12.676848Z",
"url": "https://files.pythonhosted.org/packages/30/90/c90a8ad2d78102bf12444ad7064c896ff9d8f86f1959aa64c57e93742301/rapidfireai-0.11.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-10-21 22:00:12",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "RapidFireAI",
"github_project": "rapidfireai",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"requirements": [
{
"name": "pandas",
"specs": [
[
">=",
"2.0.0"
],
[
"<",
"2.3.0"
]
]
},
{
"name": "torch",
"specs": [
[
">=",
"2.7.0"
]
]
},
{
"name": "transformers",
"specs": [
[
">=",
"4.55.2"
]
]
},
{
"name": "peft",
"specs": [
[
">=",
"0.17.0"
]
]
},
{
"name": "trl",
"specs": [
[
">=",
"0.21.0"
]
]
},
{
"name": "bitsandbytes",
"specs": [
[
">=",
"0.47.0"
]
]
},
{
"name": "nltk",
"specs": [
[
">=",
"3.9.1"
]
]
},
{
"name": "evaluate",
"specs": [
[
">=",
"0.4.5"
]
]
},
{
"name": "rouge-score",
"specs": [
[
">=",
"0.1.2"
]
]
},
{
"name": "sentencepiece",
"specs": [
[
">=",
"0.2.1"
]
]
},
{
"name": "dill",
"specs": [
[
">=",
"0.3.8"
]
]
},
{
"name": "mlflow",
"specs": [
[
">=",
"3.2.0"
]
]
},
{
"name": "pytest",
"specs": [
[
">=",
"8.4.1"
]
]
},
{
"name": "flask",
"specs": [
[
">=",
"3.1.1"
]
]
},
{
"name": "flask-cors",
"specs": [
[
">=",
"6.0.1"
]
]
},
{
"name": "requests",
"specs": [
[
">=",
"2.32.0"
]
]
},
{
"name": "loguru",
"specs": [
[
">=",
"0.7.3"
]
]
},
{
"name": "ipython",
"specs": [
[
">=",
"7.34.0"
]
]
},
{
"name": "jupyter",
"specs": [
[
">=",
"1.1.1"
]
]
},
{
"name": "ipywidgets",
"specs": [
[
">=",
"7.3.4"
],
[
"<",
"9.0.0"
]
]
},
{
"name": "uv",
"specs": [
[
">=",
"0.8.14"
]
]
},
{
"name": "tensorboard",
"specs": [
[
">=",
"2.11.0"
]
]
}
],
"lcname": "rapidfireai"
}

